
By Gordon Rugg
There’s a widespread idea that before entering formal education, people learn via “natural” learning.
It’s a warm, cosy concept; “natural” evokes thoughts of wildflowers and meadows and beauty and fluffy kittens. There’s even a certain amount of truth in it; formal education does generally involve something different from non-formal education. However, when you start looking for clear, practical, explanations of how “natural” learning actually works, you encounter a sudden silence.
There are plenty of descriptions of what “natural learning” looks like, but there’s very little discussion of how it might work, in terms of plausible cognitive or neurophysiological mechanisms. This absence makes a sceptical reader start to wonder whether there actually is such a thing as “natural learning” and whether this strand of education theory is chasing something that doesn’t exist.
In fact, there is a well-understood mechanism that accounts for the phenomena being lumped together as “natural learning” and “formal learning” (or whatever term is being used in juxtaposition to “natural learning”). However, when you look in detail at this mechanism, it soon becomes apparent that using a two-way distinction between “natural” and “non-natural” is simplistic and misleading. This is one reason that the “natural/non-natural” debate in education theory is still rumbling on, after more than two thousand years of fruitless and inconclusive argument.
In this article, I’ll discuss the mechanisms of parallel processing and serial processing, and I’ll outline some implications for education theory and practice.
The joys of nature and of fluffy kittens – not always quite the same thing…

Original images from Wikimedia
Thinking, fast and slow: Some background
There’s a concept similar to “natural learning” in other fields. The title of Daniel Kahneman’s book Thinking, Fast and Slow derives from that concept. Daniel Willingham uses similar phrasing within his book Why don’t students like school?
Both authors are well aware of the literature within cognitive psychology about how the human brain can use two different tracks for information processing. One track is fast but error-prone; the other is slow, but better at handling formal reasoning. Both are useful, for tackling different types of problem.
Neither author, though, goes into the underlying computational formalisms that are the topic of this article.
To show why this is an important point, I’ll dissect a quote that I’ve seen variously attributed to Herb Simon and to Roger Schank:
“People only use logical rational thought as a last resort.”
At first glance, this appears to be just another claim that intuition is more “natural” than reasoning. If we look at the background context, though, something very different is going on.
This quote is most often used by researchers working at the interface between computing and other disciplines (usually psychology). In this area, the quote will normally be understood to be shorthand for something along the following lines.
People only use formal classical logic and formally rational reasoning if there’s no other choice.
That’s a significant rephrasing. In the “natural versus artificial” framing, there are only two options. In the quote above, there are a lot of options, with very different implications.
“Formal classical” logic is just one type of logic. Logicians today use numerous types of logic – for instance, fuzzy logic is very different from the type of logic that Aristotle used.
Similarly, “formally rational reasoning” is very different from modern analyses of decision-making, such as the concept of bounded rationality introduced by Herb Simon, which fundamentally changed the way that economists and decision theorists view human decision-making.
The quote above is therefore very different from using the word “logical” as a label for a single type of thinking that is cool and impassive and controlled.
Instead, it’s located in a much richer and more powerful body of knowledge, grounded in a detailed understanding of the mechanisms involved in analysing and solving formal and real-world problems.
As soon as you start looking at those mechanisms, one issue jumps into centre stage. It’s taken for granted as a core distinction in computer science, but it’s little known elsewhere, even though it has major implications for a wide range of fields.
Parallel processing versus serial processing
Parallel processing involves processing two or more things at once (“in parallel”). Serial processing involves processing things one after the other (“in series”).
Here’s an example.
Suppose that you’re a builder who wants to build five houses. One approach is to work on all five of them simultaneously, as shown in the diagram below. The first red circle is the starting point; the second red circle is the finishing point. In between those two points, each house is being worked on simultaneously.
This is an example of parallel processing.
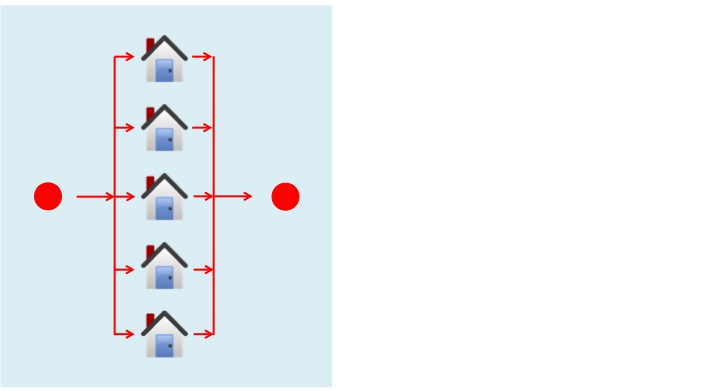
Image copyleft Hyde & Rugg, 2014, incorporating house icon from Wikimedia
This is the fastest way of getting the job done, but it comes at a price; for instance, you need to have enough staff and resources to work on all five houses at the same time, and you need to manage all those staff and resources.
A simpler and cheaper, but much slower, approach is to work on one house at a time, as in the diagram below. This is an example of serial processing.

Image copyleft Hyde & Rugg, 2014, incorporating house icon from Wikimedia
This topic has received a lot of attention in computing. The vast majority of computers use serial processing. It’s slow, in computing terms, but for most purposes the slowness isn’t a major issue – “slow” for a computer is extremely fast by human standards. Its two main advantages are that it’s much simpler and much cheaper than developing dedicated parallel processing hardware and software.
The human brain, like all animal brains, generally uses parallel processing, whose speed offers a lot of advantages in terms of selection pressures in the biological world.
Pattern matching
Speed of processing is a big advantage. Parallel processing, however, also offers another advantage which has major implications. With parallel processing, it’s easy to handle pattern matching, which is prohibitively difficult in serial processing.
Here’s an example.

Image copyleft Hyde & Rugg, 2014
The line of coloured squares above has regularities in its colouring, but those regularities don’t make a lot of sense if we process the line serially, one square at a time, going from left to right.
However, if we arrange the same squares as a grid, then we can see that there’s another pattern within them. The pattern is only easily visible if we view all the squares at once, in relation to each other, using parallel processing.

Image copyleft Hyde & Rugg, 2014
The human visual system is extremely good at pattern matching. Pattern matching is what we use to identify objects and people; it’s a key part of recognising faces. Computers, in contrast, are very bad indeed at pattern matching.
Choosing the right level of analysis: Activities and sub-activities
Although the distinction between parallel and serial processing is a clear binary distinction, in reality most non-trivial tasks involve several sub-tasks, some of which require serial processing and others of which require parallel processing. I’ll examine this in more detail in another article. It’s an important point, because when you work at the level of the lowest-level sub-tasks, then the distinction between serial and parallel processing starts to give its most powerful, practical insights.
Simply trying to categorise an entire complex task (e.g. reading) as either parallel or serial is not a good idea; it’s analogous to trying to categorise an entire machine as either metal or plastic, rather than categorising each component in terms of its material. The latter approach (i.e. looking at each individual component) works well; the former “whole task” approach just leads you into endless fruitless arguments, like the natural/non-natural distinction.
Cases where you can use either parallel or serial processing
It’s also important to note that some tasks and sub-tasks can be handled using either serial processing or parallel processing. This has significant implications for categorisations of “learning styles”.
Here’s an example of a task that can be handled either serially or in parallel. How many beads are shown in the image?

Image copyleft Hyde & Rugg, 2014
One way to find out is to use serial processing and to count them, one at a time.
Another way is to use parallel processing, and count them all in one go; this is known as subitising. Subitising can handle up to about seven items; beyond that, humans have to use serial processing and counting.
So, in summary:
Serial processing is very good at handling formal logic, and at handling numerical processing. Language involves a lot of serial processing, particularly in the case of spoken language, where the nature of speech means that words have to be spoken and heard serially, one at a time. Written language involves both serial and parallel processing, as discussed below. Humans are usually very bad at serial processing except for very limited tasks.
Parallel processing is very good at handling anything involving visual information. It’s also good at handling incomplete, imperfect, uncertain information. Humans are usually very good at parallel processing; when things go wrong with parallel processing, it’s often because of the inherent limitations of parallel processing itself, rather than the limitations of the human involved.
Some tasks can be handled using either serial processing or parallel processing.
Implications for education theory and practice
Parallel processing and serial processing are key issues in several areas that have significant implications for education theory and practice. I’ve listed some examples below; for brevity, I’ve only given very short descriptions. All of these are areas that have been researched in considerable depth, and where there is plenty of easily accessible material for any readers who want to find out more.
Implicit learning is a form of learning that does not involve any conscious awareness of the principles being learned; instead, the student learns how to do something without ever knowing just how they are doing it. A classic (though slightly surreal-sounding) example is commercial chicken sexers, who learned how to tell the sex of a young chick accurately, without ever knowing how they were able to make the distinction. Implicit learning uses parallel processing and pattern matching; it usually requires a very large number of examples, normally accompanied by immediate feedback about which category each example fits into; it usually requires a great deal of learning time.
Incidental learning is another form of learning that does not involve any conscious awareness of the principles being learned. The key difference from implicit learning is that incidental learning can occur after the student has been exposed to only one or a few examples. A classic example in the literature is the “swinging cord” experiment, where participants had to find a way of tying together two cords that were dangling from the ceiling. In one experimental condition, the experimenter “accidentally” bumped into one of the cords and set it swinging. The research participants in this condition were much more likely to spot the solution (setting both cords swinging), but typically didn’t realise that they had been inspired by the experimenter bumping into the cord.
A common form of incidental learning involves learning ways of working while in the workplace without consciously noticing all the work practices that are being learnt. This was often deliberately used as a feature of apprenticeships, where new apprentices would be given tasks such as sweeping the floor, which would give them ample exposure to the routine working practices of the experts in the workplace.
Artificial Neural Nets (ANNs) are a form of computation explicitly modelled on the neural networks in the brain. There is an extensive and sophisticated literature on this topic, which has produced numerous significant insights into the processes involved in using this computational approach, and into the implications for human cognition. An example is that this approach can have difficulties when learning some types of association, such as logical “OR” conditions.

https://en.wikipedia.org/wiki/File:Colored_neural_network.svg
This literature can appear dauntingly technical to someone encountering it for the first time. Here’s a screenshot from Wikipedia’s basic introduction to the topic.

https://en.wikipedia.org/wiki/Artificial_neural_network
The fact that it is so technical is a sign that this literature has a rich, deep, powerful understanding of the phenomenon, and that it is therefore a rich source of insights and information. It’s a world away from rehashing Rousseau’s ideas about unspoilt nature.
The level of granularity is a key issue. Attempting to shoehorn an entire complex skill such as reading into either a category of “parallel” or a category of “serial” is worse than pointless; it’s actively misleading. The distinction between parallel and serial processing only makes sense at the appropriate level of granularity. In order to find that level of granularity, you need to perform a task decomposition. Again, this is very well understood in some other disciplines. In computing, for instance, there are numerous analytical methods and corresponding notations that enable you to take a task down to the appropriate level of sub-task, and then to show which of these can or should be performed serially or in parallel.
Some examples of UML diagrams, from computing

https://en.wikipedia.org/wiki/File:UML_Diagrams.jpg
Skill compilation is a phenomenon that overlaps with pattern matching and implicit learning. It involves highly practised skills becoming so well habitualised that they can be performed without conscious thought. A classic example is a skilled driver being able to change gear while engaged in a non-trivial conversation. Compiled skills are typically performed significantly faster than non-compiled skills; they come at a price, which usually takes the form of significant amounts of practice (usually at least a fortnight, and often much longer).
Sensory issues have significant implications for whether an individual performs a task using parallel processing or serial processing. If a student has visual problems, for instance, then they might find it difficult or impossible to perform pattern matching (for example, if they have tunnel vision, and are physically unable to see the whole of the pattern simultaneously). There’s a plausible argument that this is a significant issue for people with Asperger’s, who often find it easier to learn skills via explicit serial verbal explanation than via implicit learning.
Conclusion and further thoughts
The distinction between “natural” and “non-natural” learning is not very helpful. A much more powerful approach is to draw on concepts and literatures that give more fruitful insights – in particular, the concepts of parallel and serial processing, and the literatures with which these concepts are most deeply connected.
Another key issue is the need to go to the right level of granularity when analysing a task, particularly in the case of complex tasks that consist of numerous sub-tasks and sub-sub tasks. Usually, trying to categorise an entire task as “parallel” or “serial” just doesn’t make any sense; it’s only at the appropriate level of granularity that the categorisation suddenly becomes fruitful.
The literatures on applications of these mechanisms bring home another point, namely that “natural” isn’t always the same as “easy”. For most young children, implicit learning is the “natural” form of learning; however, young children spend years acquiring skills such as language via this route. Often, information can be learned much more swiftly and efficiently via serial, explicit, verbal explanation. The situation is different again with regard to compiled skills, which are typically much faster and more efficient than performing the same task using explicit serial reasoning.
For brevity, I’ve only skimmed the surface of most of the topics mentioned in this article. However, this should give an idea of the key points involved, and of what they offer to education.
Notes
You’re welcome to use Hyde & Rugg copyleft images for any non-commercial purpose, including lectures, provided that you state that they’re copyleft Hyde & Rugg.
There’s more about the background theory for this article in my latest book:
Blind Spot, by Gordon Rugg with Joseph D’Agnese
http://www.amazon.co.uk/Blind-Spot-Gordon-Rugg/dp/0062097903
References, sources and links
I’ve blogged in more detail about concepts of nature and the natural here:
https://hydeandrugg.wordpress.com/2014/05/27/education-and-nature-part-1/
Daniel Kahneman: Thinking, Fast and Slow
http://www.amazon.com/Thinking-Fast-Slow-Daniel-Kahneman/dp/0374533555
Daniel Willingham: Why don’t students like school?
http://www.amazon.com/Why-Dont-Students-Like-School/dp/047059196X
Attributions:
The images used in the header picture:
https://commons.wikimedia.org/wiki/File:Snarling_lion.jpg
https://commons.wikimedia.org/wiki/File:Kittens_-_by_S._Mortellaro.jpg
The house in the parallel processing diagram:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Pingback: Representing argumentation via systematic diagrams, part 1 | hyde and rugg
Pingback: Connectionism and neural networks | hyde and rugg
Pingback: Things people think | hyde and rugg
Pingback: The Knowledge Modelling Book | hyde and rugg
Pingback: Observation, stumbles and smiles | hyde and rugg
Pingback: People in architectural drawings, part 6; conclusion | hyde and rugg
Pingback: Death, Tarot, Rorschach, scripts, and why economies crash | hyde and rugg
Pingback: Tacit and semi tacit knowledge: Overview | hyde and rugg
Pingback: Explicit and semi-tacit knowledge | hyde and rugg
Pingback: Tacit knowledge: Can’t and won’t | hyde and rugg